
En las últimas semanas, OpenFactura se ha visto afectada por varios incidentes que ha impactado directamente a las emisiones de DTE, recibiendo errores con código HTTP 500, 502 y 504 a través de las API, mientras en la interfaz web se vio afectada de forma diferente dependiendo del incidente. En algunos casos no era posible ingresar al sitio y en otros se presentaba un mensaje de error al intentar emitir un DTE.
Lamentamos profundamente los inconvenientes que han ocurrido en las últimas semanas generados por las intermitencias y caídas del sistema. Dentro del equipo hemos analizado los problemas para encontrar la causa raíz de los incidentes y de esta forma evitar que vuelvan a ocurrir.
Incidentes
Para dar una mejor visibilidad y entendimiento a lo que ha ocurrido en el sistema dejamos a disposición una vista general de alto nivel de los principales servicios involucrados en los incidentes, y así poder detallar las acciones aplicadas y pasos a seguir.
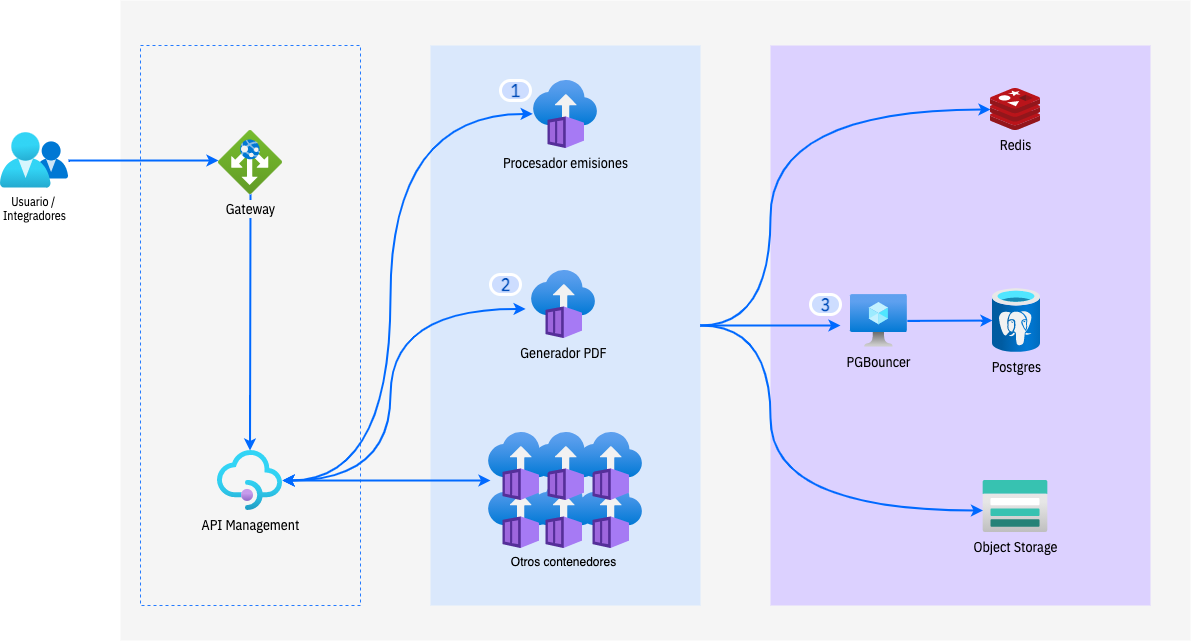
A inicio de mes se comenzaron a notar algunas intermitencias del sistema, las que si bien fueron analizadas no resultaron muy reveladoras para sacar conclusiones más acabadas.
Durante los días que revisamos las intermitencias, la base de datos comenzó a presentar una sobrecarga de conexiones gatillada principalmente por el cierre del período de agosto que lleva a nuestros más de 14.000 clientes utilizar activamente la plataforma.
Si bien son peaks normales a los que acostumbramos cada mes, esta vez algo diferente estaba ocurriendo. El sistema nos mostraba una sobrecarga de conexiones en nuestro encolador (3), generando que las nuevas conexiones tardarán más del tiempo permitido por nuestro gateway en ser procesadas -y más del tiempo normal que manejamos para las emisiones-, lo que en una primera instancia nos llevó a revisar y cambiar la configuración del PGBouncer para soportar la carga de conexiones. Desafortunadamente, esta no era la solución al problema pero nos permitió dar continuidad al sistema.
Un análisis más detallado nos llevó a que la causa del exceso de conexiones venía de un par de contenedores que estaban realizando consultas SQL que superan los 60s de ejecución sin tener un límite de tiempo para esto, causando que estas peticiones fueran reintentadas por la plataforma e ingresando una segunda consulta SQL sin aún terminar la anterior y así n-veces a través de diferentes sesiones. Adicionalmente, se encontró otro problema de configuración en uno de nuestros contenedores, el cual erróneamente estaba conectado directamente a la base de datos -saltándose nuestro encolador-.
- La primera acción fue configurar el contenedor para utilizar nuestro encolador de conexiones PGBouncer.
- Segundo fue incorporar un tiempo límite para las consultas SQL de esos servicios y así cuidar el resto del sistema ante cualquier otra eventualidad de este tipo.
- Aún pendiente se encuentra la optimización de esas consultas SQL para mejorar la experiencia de los clientes que cuentan una gran cantidad de DTE -del orden de millones de DTE mensuales-.
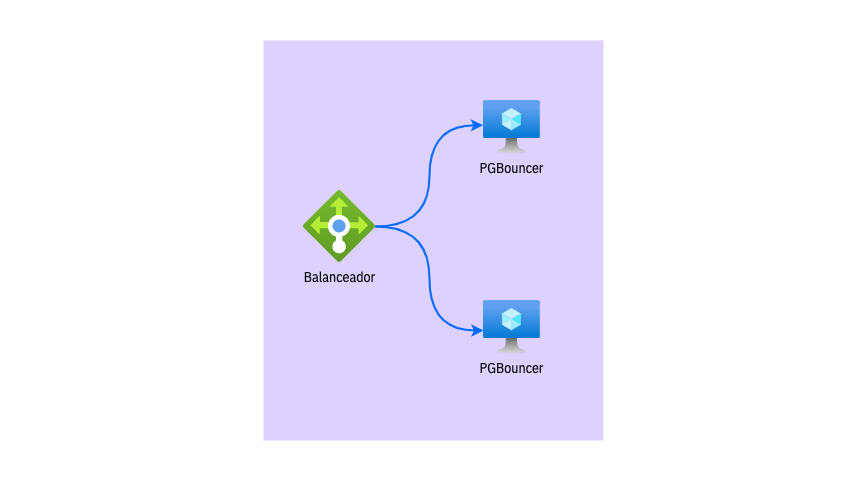
Hasta este punto se monitorea el sistema continuamente, notando una mejora considerable sobre la carga y cantidad de conexiones al sistema. Todo parecía estar yendo bien, pero repentinamente el día jueves 9 la máquina virtual que ejecuta nuestro encolador se reinició quedando en "estado inválido", siendo incapaz de iniciar.
- Somos conscientes del punto de fallo existente con nuestro encolador por lo que hoy nos encontramos trabajando en levantar una segunda instancia de la máquina virtual para evitar este punto de fallo y asegurar la estabilidad del sistema.
Desconocemos si el incidente ocurrido el día sábado fue intencional o accidental. Se estuvieron recibiendo solicitudes de emisión para PDF de 80MM con una cantidad anormal de ítems, impactando la capacidad de procesamiento de esos contenedores. Si bien se encuentran con réplicas para soportar alzas de tráfico, lo acontecido estaba fuera de lo esperado.
- Para solventar el incidente se dio más capacidad de cómputo y réplicas para soporte de un caso de uso completamente válido, ya que el SII permite hasta 1.000 ítems en un DTE.
- Por otro lado, se encontró un problema de configuración en el servicio encargado de generar los PDF de 80MM. Este tiene un límite de respuesta de 4 minutos, lo que contradice las reglas del Gateway, generando un exceso de carga al forzar reintentos al cliente sin haber terminado su solicitud inicial.
Hallazgos claves
Encontramos puntos de mejora que involucran a nuestros procesos y tecnología.
- Tecnológicamente debemos comprobar y confirmar que todos nuestros sistemas tienen la configuración correcta.
- A nivel de procesos debemos reforzar y mejorar nuestro control de cambios, evitando que un nuevo servicio/contendor sea puesto en producción con una configuración incorrecta.
- Adicionalmente, nuestra comunicación no fue llevada de forma eficaz, generando mucho confusión e incertidumbre durante los incidentes.
Conclusión
Reconocemos el impacto que estos incidentes tienen en nuestros clientes y cómo estos dañan la confianza que ustedes han depositado en nosotros, lo lamentamos profundamente.
Queríamos compartir detalles más específicos sobre los problemas recientemente ocurridos para darles claridad de cómo están siendo manejados y cómo ocurrieron. Hemos detectado los hallazgos claves que nos permitirán mejorar y entregar un mejor servicio.
El equipo completo de OpenFactura está comprometido en dar el mejor servicio a nuestros clientes y comunidad de integradores. Y continuaremos trabajando para que siempre sea así.
Juan Manuel Parraguez
Gerente de Tecnología